JSP (Java Server Pages) are virtually identical to ASP (Classic ASP) in every respect, with a little .NET (ASPX) thrown in.
They begin to differ here:
http://www.jsptut.com/Forms.jsp
That's where a BEAN is used, like ASP.NET MVC will use a Model.
ASP.NET MVC was probably the attempt to emulate more of what JSP were doing, since they started the MVC thing (maybe with ?Struts?)
Wednesday, February 15, 2017
Hashtables vs. Arrays
Original post by Kirupa in 2010:
https://www.kirupa.com/html5/hashtables_vs_arrays.htm
According to Kirupa, unless you need to iterate (loop) through your data, use a hastable. But what about using: for(x in MyData)?
https://www.kirupa.com/html5/hashtables_vs_arrays.htm
According to Kirupa, unless you need to iterate (loop) through your data, use a hastable. But what about using: for(x in MyData)?
Two data structures that you probably use frequently are hashtables and arrays. On the surface, they both allow you to perform common tasks such as adding data, accessing data, and removing data. To the untrained eye, they practically look like the same thing. What sets them apart is how they work behind the scenes, and this difference has a significant impact in how and when you would use them.
By the end of this tutorial, you will have learned enough about how hashtables and arrays work to make an informed decision on which data structure to use. Let's get started!
The Data
To better help explain the differences between arrays and hashtables, I am going to use some sample data from Wikipedia on best-selling artists and how many records they've sold:
Artist
|
Certified Sales (millions)
|
The Beatles
|
248.3
|
Elvis Presley
|
201.2
|
Michael Jackson
|
155.8
|
Madonna
|
157.8
|
Elton John
|
153
|
Led Zeppelin
|
133.4
|
Queen
|
88.2
|
ABBA
|
54.4
|
Mariah Carey
|
118.2
|
Celine Dion
|
111.4
|
Pink Floyd
|
110.1
|
AC/DC
|
99.3
|
The Rolling Stones
|
89.5
|
Bee Gees
|
63.2
|
What we want to do is store these values and then retrieve the number of albums sold for any given artist. For example, if I wanted to know the sales figures for the Rolling Stones, I should be able to get 89.5 from my application very quickly.
In the following sections, you'll see how to do that using both arrays and hashtables.
Examining Arrays
Let's start with our friendly array. If I wanted to store my data in an array, the JavaScript will look as follows:
- <script>
- var myData = [];
- myData.push(["The Beatles", "248.3"]);
- myData.push(["Elvis Presley", "201.2"]);
- myData.push(["Michael Jackson", "155.8"]);
- myData.push(["Madonna", "157.8"]);
- myData.push(["Elton John", "153"]);
- myData.push(["Led Zeppelin", "133.4"]);
- myData.push(["Queen", "88.2"]);
- myData.push(["ABBA", "54.4"]);
- myData.push(["Mariah Carey", "118.2"]);
- myData.push(["Celine Dion", "111.4"]);
- myData.push(["Pink Floyd", "110.1"]);
- myData.push(["AC/DC", "99.3"]);
- myData.push(["The Rolling Stones", "89.5"]);
- myData.push(["Bee Gees", "63.2"]);
- </script>
I am creating a new array called myData. Initially, this array is empty, but I painstakingly add each artist and their sales figures. Notice that the artist information that I push into the myData array is wrapped in an array of its own as shown by the brackets. After all of this code has run, you have an array that contains many other arrays.
Populating our array is only one part of what we are trying to do. What we really want is to be able to easily find the sales figures for a particular artist. Remembering that myData's items are arrays themselves, the code for retrieving the sales figure given an artist is:
- <script>
- var myData = [];
- myData.push(["The Beatles", "248.3"]);
- myData.push(["Elvis Presley", "201.2"]);
- myData.push(["Michael Jackson", "155.8"]);
- myData.push(["Madonna", "157.8"]);
- myData.push(["Elton John", "153"]);
- myData.push(["Led Zeppelin", "133.4"]);
- myData.push(["Queen", "88.2"]);
- myData.push(["ABBA", "54.4"]);
- myData.push(["Mariah Carey", "118.2"]);
- myData.push(["Celine Dion", "111.4"]);
- myData.push(["Pink Floyd", "110.1"]);
- myData.push(["AC/DC", "99.3"]);
- myData.push(["The Rolling Stones", "89.5"]);
- myData.push(["Bee Gees", "63.2"]);
- var artist = "The Rolling Stones";
- for (var i = 0; i < myData.length; i++) {
- if (myData[i][0] == artist) {
- alert("Sales for " + artist + " is " + myData[i][1]);
- }
- }
- </script>
Notice that I create a loop to go through each item in our array and check if the first value in the item's array (myData[i][0]) is the same as the artist we are looking for. Once the item and the artist match, we retrieve the sales figure and call it a day.
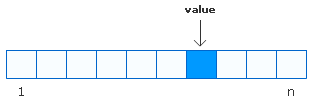
To look at this example more generically, let's we have an array with n items with a value somewhere that we are interested in:
If you had no idea where the value is and wanted to find it, you'll need to start at the beginning of your array and then move through each item and check if its contents match the value you are looking for.
If your value is at the beginning of the array, you won't have too many items to go through resulting in you finding the value quickly. If your value is at the end of the array, you'll have to go through a lot of items and take more time finding the value.
On average, we say that the amount of time it takes to find a value in an array is proportional to the number of items in your array. The more items, the longer it will take to find an item.
Examining Hashtables
Now that you have an idea of how arrays search for data, let's see how a hashtable would handle a similar scenario.
The code for adding data using a hashtable looks as follows:
- <script>
- var myData = new Object();
- myData["The Beatles"] ="248.3";
- myData["Elvis Presley"] ="201.2";
- myData["Michael Jackson"] ="155.8";
- myData["Madonna"] ="157.8";
- myData["Elton John"] ="153";
- myData["Led Zeppelin"] ="133.4";
- myData["Queen"] ="88.2";
- myData["ABBA"] ="54.4";
- myData["Mariah Carey"] ="118.2";
- myData["Celine Dion"] ="111.4";
- myData["Pink Floyd"] ="110.1";
- myData["AC/DC"] ="99.3";
- myData["The Rolling Stones"] ="89.5";
- myData["Bee Gees"] ="63.2";
- </script>
To explain the code a bit, I first create a new Object called myData. Inside myData, I declare properties/keys named after our artists with the values set to the artists' sales figures.
To retrieve a particular sales record, all you do is pass the property (the artist name) to the myData object:
- <script>
- var myData = new Object();
- myData["The Beatles"] ="248.3";
- myData["Elvis Presley"] ="201.2";
- myData["Michael Jackson"] ="155.8";
- myData["Madonna"] ="157.8";
- myData["Elton John"] ="153";
- myData["Led Zeppelin"] ="133.4";
- myData["Queen"] ="88.2";
- myData["ABBA"] ="54.4";
- myData["Mariah Carey"] ="118.2";
- myData["Celine Dion"] ="111.4";
- myData["Pink Floyd"] ="110.1";
- myData["AC/DC"] ="99.3";
- myData["The Rolling Stones"] ="89.5";
- myData["Bee Gees"] ="63.2";
- alert(myData["ABBA"]);
- </script>
That's all you have to do. When you call myData["ABBA"], your browser evaluates that to 54.4. That's all there is to it. What you write is clean and simple, but what goes on behind the scenes is more complex.
Hashtables work by finding the exact location your value is stored and returning that value instantaneously or nearly instantaneously. You may be wondering how that is done.
Let's first look at a simplified view of how a hashtable works:
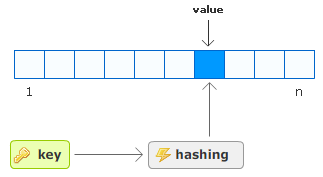
When you add data to a hashtable, you specify both a key and a value to go with it:
- myData["Pink Floyd"] ="110.1";
In the above case, the key is "Pink Floyd", and the value is 110.1.
When your hashtable sees this key, it passes it through what sounds like a painful process called hashing, and the output of this hashing function is a number indicating where in the hashtable our value needs to go.
If you want to retrieve the value from the hashtable, all you have to do is provide the same key. When your hashtable sees this key, the hashing function returns the same number of the location inside the hashtable containing your value. Once you have this number, the hashtable has no difficulty retrieving the exact value.
Unlike with the array, notice that you did not have to scan through your hashtable to find the value. Because the hashing function returns the same index number for the same key, the hashtable knows exactly where to go to retrieve the value.
Conclusion
The following table summarizes the memory and performance characteristics of hashtables and arrays:
Task
|
Average Complexity
|
Memory (hashtable)
|
O(n) - Linear
|
Memory (array)
|
O(n) - Linear
|
Inserting (array)
|
O(1) - Constant
|
Search (array)
|
O(n) - Linear
|
Delete (array) - middle
|
O(n) - Linear
|
Delete (array) - beginning/end
|
O(1) - Constant
|
Inserting (hashtable)
|
O(1) - Constant
|
Search (hashtable)
|
O(1) - Constant
|
Delete (hashtable
|
O(1) - Constant
|
From a performance point of view, the hashtable is generally a clear winner. It takes constant time to find the destination for a key and to place a value there. Retrieving a value is the same story. The hash function ensures that for the same key the same location of the bucket is returned.
Arrays do not work with that same level of efficiency. If you know the index position of where your item is, accessing the item via the array is instantaneous. More than likely, you do not know where the item in the array the item you are looking for is. In these cases, you will have to scan through your items which linearly takes as much time as the number of items in your array.
Not everything is about efficiency though. Sometimes, you will want to use an array if you will be iterating through the items. Iterating through your data sounds simple, but it isn't something you can easily do with a hashtable. I know, bummer!
Subscribe to:
Posts (Atom)